


Блог:
Замена жестких дисков HDD (Raid 1) на сервере Intel
21.03.2021 20:52
Недавно столкнулся с ситуацией, когда жесткие диски потихоньку умирали, при этом Raid- контроллер, не информировал об этом в явном виде, и только по косвенным признакам удалось понять, что с хардами есть проблемы.

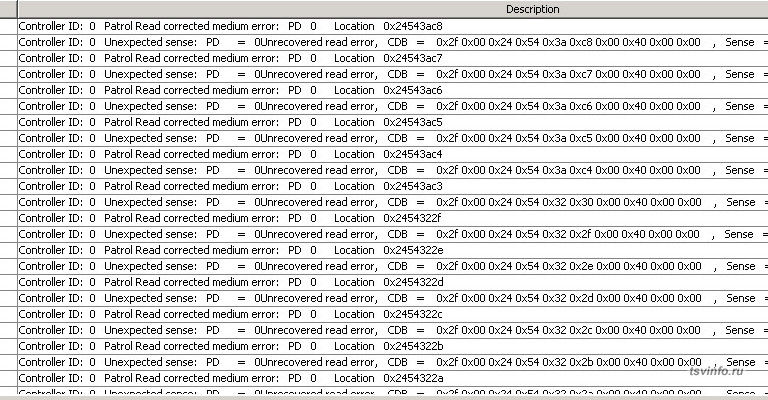
Предыстория была такая, сотрудники организации начали жаловаться, на появившиеся подтормаживания при работе на сервере. При этом в логах самой операционной системы, никаких отклонений найдено не было. Исследуя дальше, заглянул в Intel RAID Web Console, и ее в логах обнаружил часто повторяющие записи:
Unexpected sense: PD = -:-:0Unrecovered read error
с номером ошибки 113 и
Patrol Read corrected medium error
с номером ошибки 93, а по окончанию сканирования появлялись записи:
VD is now DEGRADED VD 0
Rebuild started: PD -:-:1
Rebuild automatically started: PD -:-:1
и это означало о сбоях в работе рейд массива.
Сам массив работал в режиме зеркала (Raid 1), поэтому сбои в работе с жестким диском, не вызывали явных проблем в работе, за исключением небольших подтормаживаний в тяжелых эксплуатационых режимах, и то в момент пересоздания массива.
В информации о жестких дисках, у одного диска параметр Media Error Count был равен нулю, а вот у второго был более двух тысяч.
После замены жестких дисков на новые, проверил состояние демонтированных дисков. Проверку дисков осуществлял в отлично зарекомендовавшей себя MHDD, к сожалению программа работает только из под DOS и в режиме IDE, новомодные AHCI и работа через Raid не поддерживается.
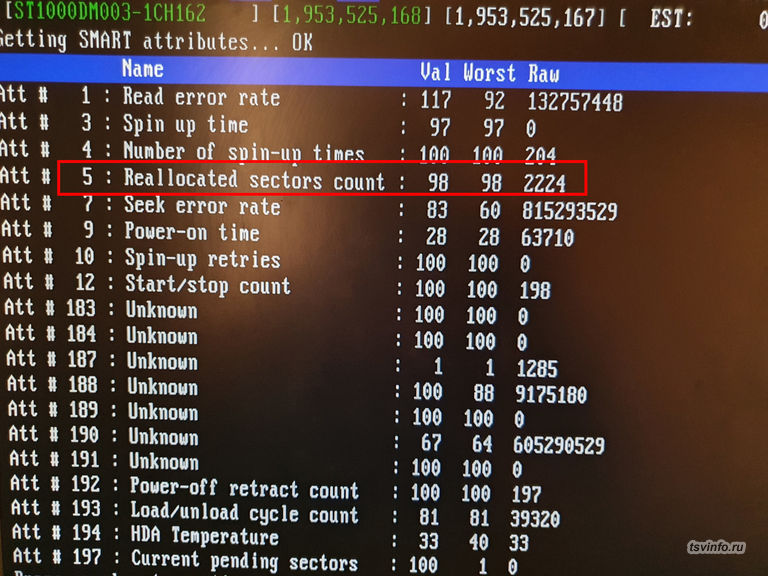
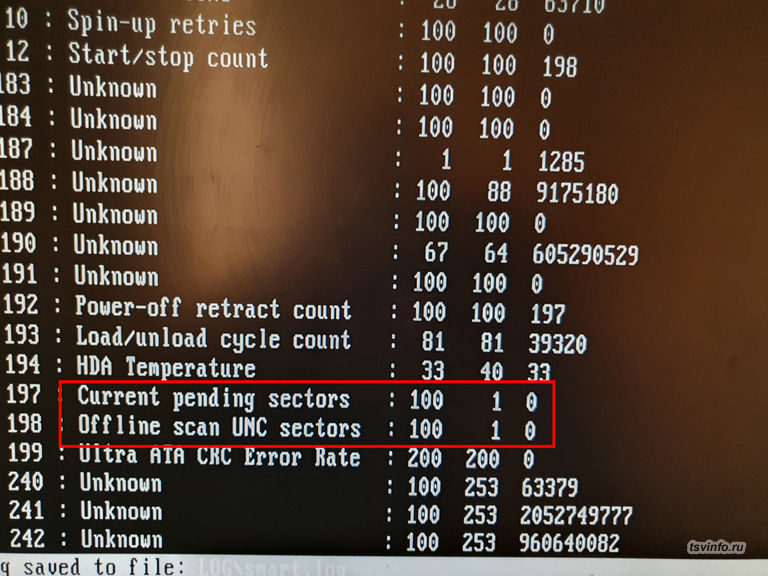
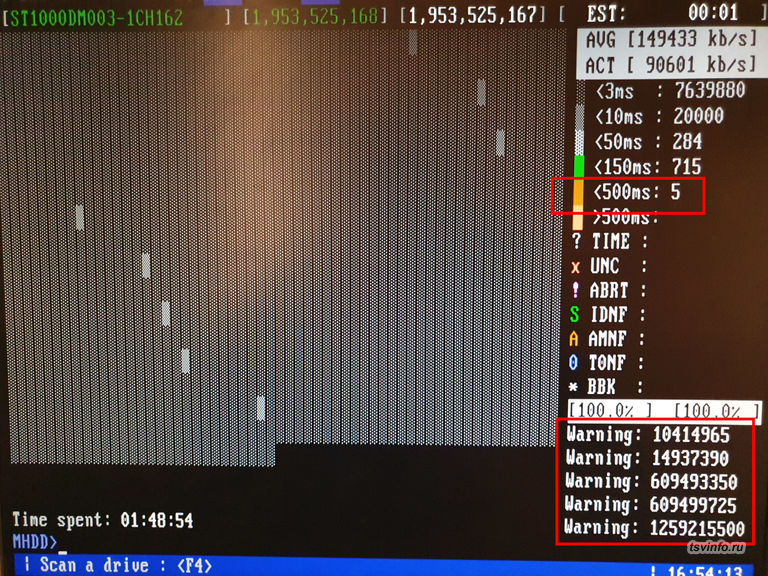
Сперва проверил диск, на который ругался Raid-контроллер. Опасения подтвердились. В SMART диска, Raw значение у параметра Rellocated Sector Count имело значение равное 2224 (в идеале должно быть 0), при этом Val и Worst были равны 98 (должно быть 100), так же на себя обратили параметры Current pending sector и Offline scan UNC sector со значением Worst равному 1 (должно быть 100). Проверка чтения диска показала, 5 плохо читаемых секторов, и 715 с ухудшением чтения (в идеале цветных не должно быть). В общем, с этим диском все ясно, для серьезных задач он не подходит, но вполне можно использовать там, где нет риска потерять информацию. Теперь следующий диск.
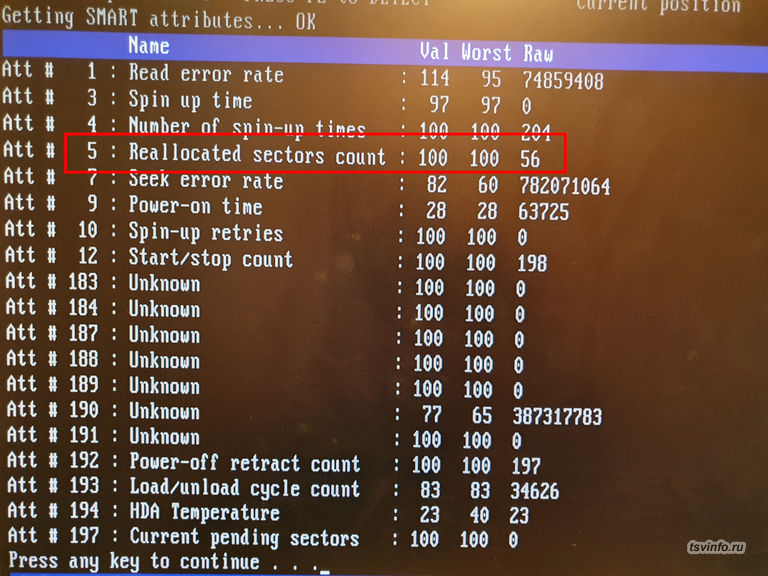
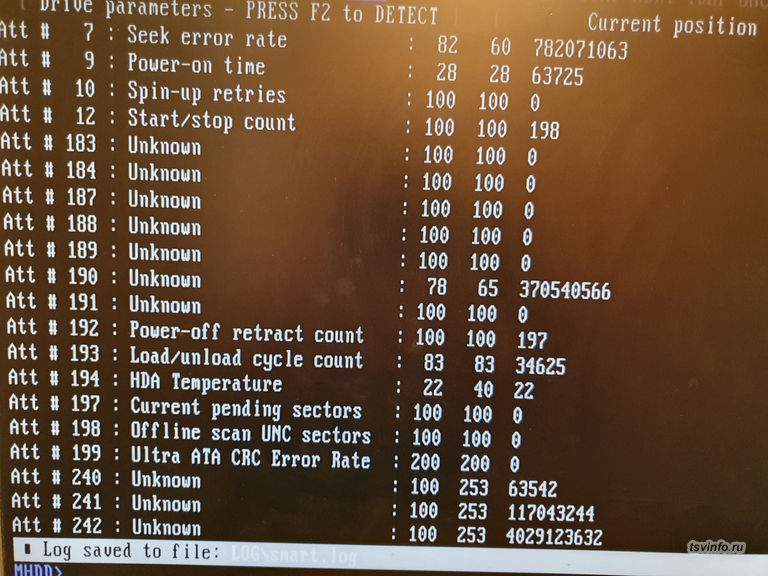
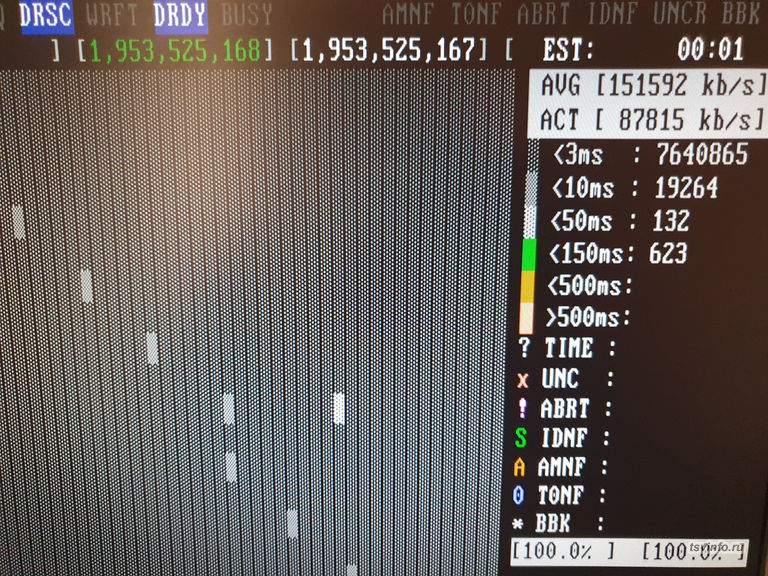
А вот у него, вопреки моим ожиданиям (контроллер то на него не ругался), значение Raw параметра Rellocated Sector Count было равным 56, а это означало, что второй диск тоже начинал потихоньку подсыпаться, и к сожалению рейд-контроллер, никак не сообщал об этом. Остальные параметры в норме, разве что 623 сектора с ухудшенным чтением, но в серьезных задачах использовать его, как и первый уже точно нельзя. Вообще, не знаю почему, но производители рейд-контроллеров не хотят сделать вывод параметров SMART жестких дисков. Для визуального контроля, этой функции категорически не хватает. Уставшие диски были производства Seagate, модель ST1000DM003. Установлены они были в 2013 году, учитывая, что они не корпоративного сегмента, то вполне отслужили свое.

Теперь о нюансах связанных с заменой дисков, как оказалось перестройка массива в утилите вшитой в BIOS идет крайне долго. Для 1ТБ диска за 3 часа выполнилось всего 15%, а вот в утилите из под Windows, за это время диск полностью перестроил массив, поэтому если нужно быстро, то ребилд выполняйте только из под "винды".
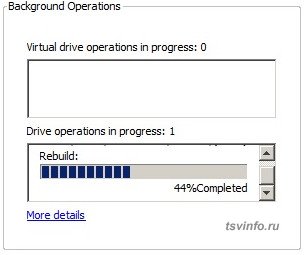
На замену сбойным дискам, установил WD Gold 1TB (WD1005FBYZ). Видимо, из-за странных особенностей этих дисков, при включении, в течение 1-2 минут, появляются зеленые блоки в MHDD (возможно диск делает какие-то рекалибровки), потом те же самые места проходят без проблем. И еще при выключении, очень шумно, с каким-то диким скрежетом срабатывают тормоза, ни на каком другом диске, ранее такие звуки мне не встречались. Сам же сервер не имеет Hot Swap корзин, поэтому при замене дисков был полностью продут от пыли, за что сервер точно скажет спасибо!